
web開発をしている中で、全体像を把握するときに、バックエンド側の知識もつけないと辛いなという場面が多々出てきたため、重い腰を上げてSQLを勉強しました。
SQLとMySQLの違いもわからなかったくらいの初心者なので、何か間違いあればご指摘ください。
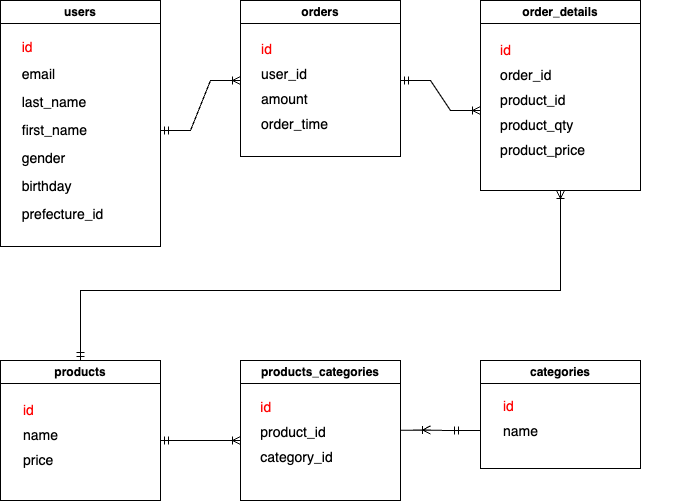
ER図
基本構文
テーブルからユーザー情報を取得
select * from users;テーブルから商品情報の名前と価格を取得
select name, price from products;列に別名をつける
select name as 名前, price as 価格 from products;※asは省略可能
列の値に対して演算を行う
select name, price, price * 1.08 from products;条件を指定してデータを取得
例)ー価格が9800円以上の商品を取得
select name, price from products where price >= 9800;例)idが1の行を取得
select * from products where id = 1;likeによる絞り込み
例)「中」から始まる苗字の人を抽出(中村、中川など)
select * from users where last_name like ‘中%’;ワイルドカード文字
%・・・ 0文字以上の任意の文字列
_ ・・・任意の1文字
| 中% | 中で始まる文字列 |
| %中% | 中を含む文字列 |
| %子 | 子で終わる文字列 |
| __子 | 何かしらの2文字から始まり子で終わる文字列 |
取得件数を制限する limit句
select * from products limit 10;例)0番目から10件表示
select * from products from 0, 10;例)10番目から10件表示
select * from products from 10, 10; ※何件データがあるかわからない場合はlimitを書いておくとトラブル防止になる
合計値を求めるsum集約関数
例)2017年1月の販売金額の合計を求める
select sum(amount) from orders
where order_time >= “2017-01-01 00:00:00” and order_time < “2017-02-01 00:00:00”;例)価格の平均値を求める
select avg(price) from products;価格の最小値を求める
select min(price) from products;価格の最大値を求める
select max(price) from products;対象行の数を数える
select count(*) from users;月間ユニークユーザー数を求める
例)2017年1月1日にアクセスしたUU数
select count(distinct user_id) from access_logs where request_month = “2017-01-01”データをグループ化する
例)都道府県別に集計
select prefecture_id, count(*) from users group by prefecture_id;集約結果を絞り込むhaving句
例)2017年の月毎のUU数が630人以上の月を絞り込む
select request_month, count(distinct user_id) from access_logs
where request_month >= “2017-01-01” and request_month < “2018-01-01”
group by request_month having count(distinct user_id) >=630;並び替え
例)商品一覧の価格の高い順に並び替え
select * from products order by price desc;例)商品一覧の価格の低い順に並び替え
select * from products order by price (asc);複数の並び替え条件を指定する
例)商品一覧を価格が高い順に並べて、価格が同じ時は登録順で並び替え
select * from products order by price desc, id asc;四捨五入 round
round(対象の数値,丸めの桁数)
例)税込み価格を出力し、少数第1位で四捨五入
select id, name, round(price * 1.08, 0) from products;文字列の演算
例)山田 太郎さんのように苗字+スペース+名前+さんの形で出力(MySQLではconcat関数を使う)
select concat(lase_name, “”, first_name, “さん”) from users;内部結合でテーブルを結合する inner join
例)都道府県IDではなく都道府県名で表示
select users.id, users.last_name, users.first_name, prefectures.name
from users inner join prefectures on users.prefecture_id = prefectures.id;内部結合+絞り込み
例)上記+女性だけのデータに絞り込み
select users.id, users.last_name, users.first_name, prefectures.name
from users inner join prefectures on users.prefecture_id = prefectures.id
where users.fender = 2;外部結合
例)全ての商品の販売個数を一覧で取得
select p.id p.name sum(od.product_qty) num from products p
left outer join order_details od on p.id = od.product_id group by p.id;データの更新
新規データの追加
insert into products (name, price) values (“新商品A”, 1000);列リストを省略して1件レコードを追加
insert products values (1002, “新商品B”, 2000);行を複数追加
insert into products (name, price) values (“新商品C”, 3000), (“新商品D”, 4000), (“新商品E”, 5000);レコードの更新
例)価格を10%引きした価格に変更
update products set price = price * 0.9;特定の条件に合致するデータを更新
update products set name = “SQL入門” where id = 3;行の削除
delete from products_categories;条件を指定して行を削除
delete from products where id = 1001;サブクエリ
・ある問合せの結果に基づいて、異なる問い合わせを行う仕組み
・複雑な問い合わせができ、where句の中で使うことが多い
・日々の業務改善のデータ分析に役立つデータが、DBから直接SQLで取り出せる
(全商品の平均単価より、高い商品を取得 / 商品別の平均販売量より、多く売れている日を取得)
例)2017年12月に商品を購入していないユーザーにメルマガを出したいから該当ユーザー一覧を出して欲しい、user_id、名字、emailが欲しい
select id, last_name, email from users
where id not in (select user_id from orders where order_time ≥ “2017-12-01 00:00:00”
and order_time < “2018-01-01 00:00:00”);DBの追加
create database book_store;テーブルの追加
create table books(id int not null auto_increment primary key, title varchar(255) not null );テーブル構造の変更
例)booksにpriceを追加
alter table books add price int after id;例)priceをunit_priceに変更したい
alter table books change price unit_price int;例)booksからunit_priceを削除
alter table books drop unit_price;テーブルの削除
drop table books;DB削除
drop database book_store;


